It's Not a Prompt Problem — It's a Context or Harness Problem

Have you ever spent half an hour refining a prompt — making the instructions clearer, more detailed, adding examples, adding constraints — and the agent kept failing in exactly the same way?
You've been there: the model hallucinates even with a perfect prompt. Or worse: the agent acts on the world, does something it shouldn't, and you find out in production. Not in the test chat, not in the sandbox. In production, with real data.
That's not a prompt problem. And polishing the system prompt text won't fix it.
This article is about understanding where the problem actually lives — and why conflating these three layers of AI engineering wastes time, money, and sometimes causes incidents.
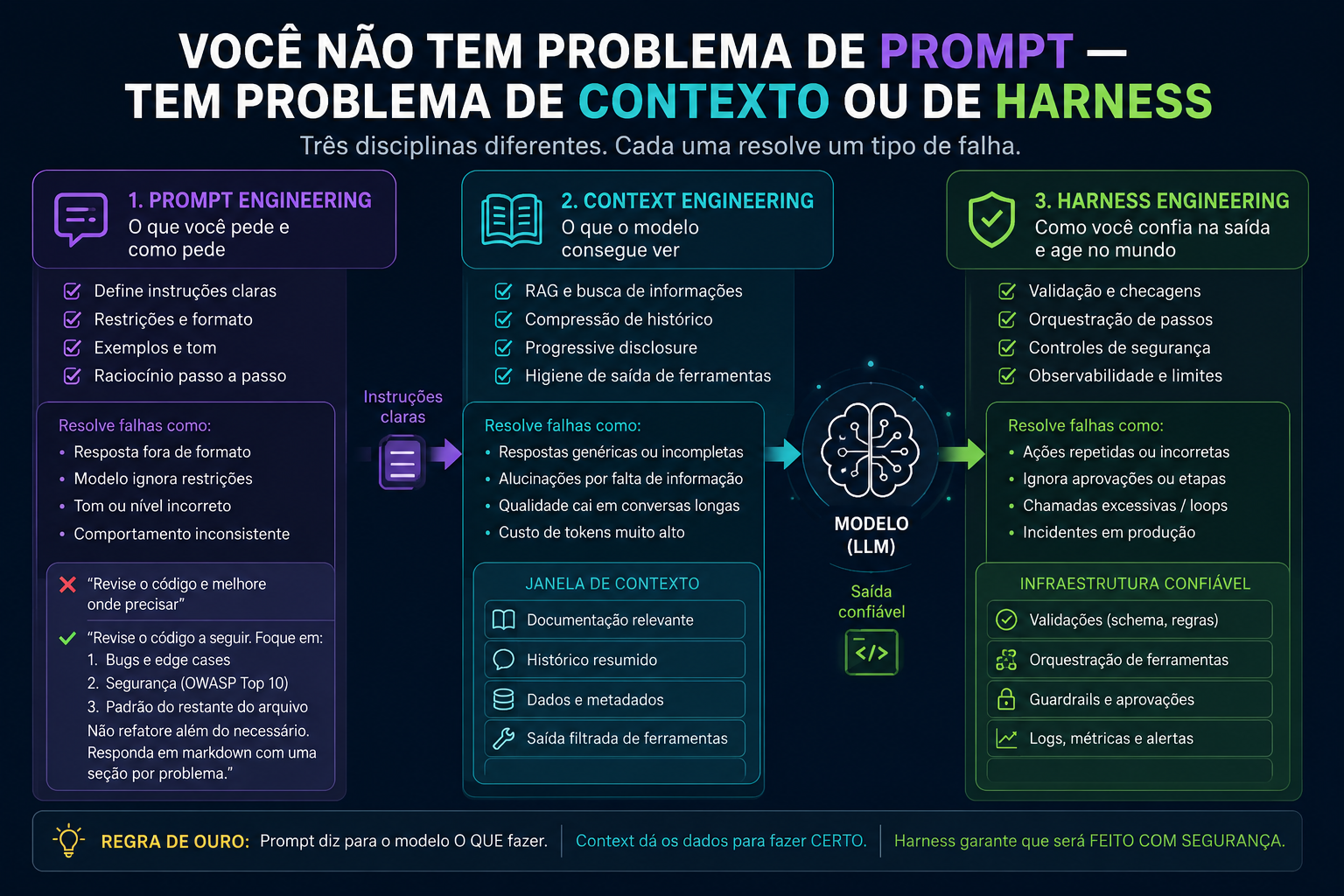
The three disciplines that became synonyms (and shouldn't be)
The market threw everything into the same bucket: "prompt engineering." Want the model to answer better? Write a better prompt. Want a more reliable agent? Better prompt. Want to reduce hallucinations? Better prompt.
It works at a basic level. But once you start building real things — an agent that reads files, opens PRs, sends emails, queries a database — that view starts to crack. And the cracks show up exactly where it hurts most: in production.
Andrej Karpathy was one of the first to name this clearly: what most people call prompt engineering is actually Context Engineering — "the delicate art and science of filling the context window with just the right information." And there's a third layer that almost nobody talks about: the Harness — the infrastructure that wraps the model and converts probabilistic output into reliable software.
These are three separate disciplines. Each one solves a different set of failures. Confusing them leads to effort in the wrong place.
Prompt Engineering: what you ask and how you ask it
Prompt Engineering is the most visible layer. This is where you define:
- The model's role ("you are a senior code reviewer...")
- Constraints ("never delete files without confirming")
- Response format (JSON, markdown, numbered list)
- Behavioral examples (few-shot)
- Step-by-step reasoning (chain-of-thought)
It's a real discipline with real techniques and real results. When the model produces inconsistent output, wrong format, wrong tone, or does things you explicitly said not to do — you have a prompt problem.
The most common mistake here is being vague. The model won't "understand what you meant." It will follow what you wrote.
❌ "Review the code and improve wherever needed"
✅ "Review the following code. Focus on:
1. Bugs and unhandled edge cases
2. Security violations (OWASP Top 10)
3. Inconsistencies with the rest of the file's patterns
Don't refactor beyond what's necessary. Respond in markdown
with one section per issue found."
When to invest in prompts:
- The response comes in the wrong format
- The model ignores constraints you defined
- The tone or level of detail is off
- Behavior is inconsistent across similar calls
When to stop tweaking the prompt: When the model answers correctly for what you asked, but the information it has is wrong or incomplete. That's not a prompt problem.
Context Engineering: what the model can see
This is where the game changes. And where most real agent failures in production actually live.
Context Engineering is the discipline of deliberately assembling the context window — deciding what goes in, what stays out, in what order, at what granularity. It's not a static text. It's a dynamic construction per turn.
A concrete example: you have a support agent that answers technical questions. The prompt is impeccable. But the agent hallucinates information about your product's API. Why?
Because nobody put the up-to-date documentation into the context window. The model is answering based on what it learned during training — which may be outdated, incomplete, or simply wrong for your specific product.
That doesn't get fixed with a prompt. It gets fixed with Context Engineering:
- RAG (Retrieval-Augmented Generation): retrieves the relevant documentation excerpts and injects them before the question
- History compression: in long conversations, summarizes old interactions instead of sending everything every time
- Progressive disclosure: sends metadata first (filenames, headers) and only expands to full content when necessary
- Tool output hygiene: when the agent calls an API that returns 50KB of JSON, you don't put all of it in the window — you filter, truncate, extract what matters
Shopify's CEO Tobi Lütke put it well: context engineering is "the art of providing all the context for the task to be plausibly solvable by the LLM." Telling it what to do isn't enough — the model needs the facts to do it right.
When to invest in context:
- The model gives generic answers when it should be specific
- Hallucinations decrease when you manually paste documentation into the chat
- In long conversations, quality drops as history grows
- Token costs explode with number of users
When to stop tweaking the context: When the model sees the right data but the agent still acts wrong — commits the same action twice, skips an approval step, or blows past its call budget. That's a harness problem.
Well-assembled context window:
[System Prompt] ← what the model is and what it must not do
[Relevant documentation] ← retrieved via RAG, not static
[Compressed history] ← summary of last N interactions, not the full log
[Current system state] ← what changed since the last action
[Filtered tool outputs] ← only what matters from tool responses
[Current turn request] ← what the user is asking now
Harness Engineering: what wraps the model
This is the layer almost nobody talks about — and the one that makes all the difference once an agent starts acting on the world.
The harness is all the infrastructure surrounding the model. Not what you ask (prompt), not what the model sees (context). It's the complete loop that converts the model's probabilistic output into software that behaves predictably:
- Orchestration cycle (plan → call tool → observe → repeat)
- Timeouts and retries when tools fail
- Sandboxing to limit what the agent can touch
- Approval gates before irreversible actions
- RBAC: the model can only call tools the current user has permission for
- Idempotency: if the same action runs twice, the result is the same
- Circuit breaker: agent spent $X in tokens? Stop. Called the same endpoint 30 times? Stop.
- Audit trail: log everything the agent did, with what inputs, with what results
If you have a coding agent (like Claude Code, Cursor, or your own) that proposes file edits — who applies the patch, runs the tests, verifies nothing broke, and stops on failure? Not the model. The harness.
If the agent can send an email, create a Jira ticket, or merge a PR — who decides that action needs human approval before executing? Not the prompt. The harness.
The AI hype cycle still markets Prompt Engineering as the primary skill. The production pain lives in Context and Harness. This is exactly where production incidents happen, where costs explode, and where user trust disappears.
When to invest in the harness:
- The agent can act on the world (not just respond — it executes, modifies, sends)
- You need auditability ("who authorized this?")
- Costs scale with users in unexpected ways
- The agent works in the demo but doesn't survive real conditions
- Actions repeat, or the agent loops without a stopping criterion
Classic harness failure symptom: everything works in the playground. In production, with real users, under load, with intermittent API failures — the agent gets stuck in a loop, executes the same action twice, or doesn't stop when it should.
How to diagnose which layer your problem is in
This has saved me a lot of time. Before touching anything, ask:
Is the model responding with something wrong or in the wrong format?
→ Prompt problem. Revise the instructions, add examples, be more specific.
Is the model responding correctly for what it saw, but what it saw was wrong or incomplete?
→ Context problem. Improve retrieval, filter tool outputs better, compress history.
Is the model responding correctly and seeing the right information, but the agent as a system still fails?
→ Harness problem. Missing approval gate, missing idempotency, missing circuit breaker, missing log.
A quick reference table:
| Symptom | Layer |
|---|---|
| Response in the wrong format | Prompt |
| Response ignores explicit constraint | Prompt |
| Hallucinates fact that was in the documentation | Context |
| Token costs explode with users | Context |
| Quality drops in long conversations | Context |
| Agent acts twice on the same thing | Harness |
| Demo works, production doesn't | Harness |
| No record of who did what | Harness |
| Agent doesn't stop when it should | Harness |
The agent maturity ladder
This follows a natural progression as the agent becomes more capable:
Stage 1 — Copilot/Q&A: Responds, suggests, doesn't act. Well-written prompt plus minimal context (maybe some RAG). The harness is basically rate limiting and logging.
Stage 2 — Tool-using assistant: Calls APIs, reads databases, generates artifacts. Context Engineering becomes mandatory — tool output needs to be curated per turn. The harness defines the tool surface and error handling.
Stage 3 — Operational agent: Acts autonomously, executes complete workflows, scales to multiple users, integrates with external systems. Here the harness dominates. Approvals, shared policy, idempotency, audit trails, unified actions across channels.
Most teams are trying to build Stage 3 with only Stage 1 Prompt Engineering. That's where the frustration comes from.
What I learned the hard way
I went down the wrong path multiple times, in this exact order:
First mistake: endlessly adjusting the prompt when the agent was hallucinating because it didn't have the information. I spent hours trying to make the model "not make things up" through instructions. The fix was putting the right document in the context window.
Second mistake: piling on context without a plan. Assuming more information always helps. It doesn't. A large window full of noise is worse than a small window with the essentials. The model gets lost in the middle.
Third mistake (the worst): letting the agent act without a harness because "it was working in tests." Then in production it executed an action twice because the API timed out on the first attempt and it interpreted that as failure. Without idempotency in the harness, without a verification gate before re-executing — guaranteed problems.
Before building an agent that acts on the world, answer this checklist:
- What happens if the tool fails? (retry? fallback? stop?)
- What happens if the action runs twice? (idempotent? duplicates data?)
- Is there an irreversible action here? (if yes, needs an approval gate)
- How do I trace what the agent did? (no log = guaranteed problem)
Conclusion
The distinction isn't just semantic. It's diagnostic.
When you understand these are three separate layers, you stop spending energy in the wrong place. You're not polishing a prompt when the problem is context. You're not stuffing more tokens into the window when the problem is a missing approval gate.
Prompt Engineering solves how the model understands what you want.
Context Engineering solves whether the model has the right information to act.
Harness Engineering solves whether the system surrounding the model is reliable enough to go to production.
A good production agent needs all three. What changes is the proportion — and knowing which one is holding you back.